AMD has published a patent application to spread the rendering load across multiple GPU chipsets, which provides some interesting insights. To optimize the use of shaders in games, the game scene is divided into individual blocks and distributed to chiplets. Two-level binning is used for this.
A whole wave of new patent applications
With a veritable flood of patent filings published over the past week, AMD has potentially revealed a wealth of new insights into upcoming GPU and CPU technologies. On June 30 alone, 54 patent applications were published. It remains to be seen which patents will ultimately be approved and which will actually be found in products. Regardless of this, the apps provide interesting insights into the technological approaches pursued by AMD.
is particularly interesting Patent application US20220207827 to the two stage Group of image data in order to better distribute the rendering loads of a GPU to multiple chiplets. AMD had already submitted the application at the end of December 2021.
The classic load sharing in shaders
Traditionally, rasterizing image data on a GPU works relatively simply: each GPU Shader Unit (ALU) can perform the same task, that is, assign a color to individual pixels. For this, the texture TECH GAMING REPORT located at the corresponding pixel location in the game scene is mapped onto the pixel. Since the calculation task is always the same in principle and only differs due to different textures at different points in the scene, the working method is called “Single Instruction – Multiple Data” (SIMD).
In modern games, this calculation step called “shading” is no longer the only task of a GPU. Instead, a host of post-processing effects are now added as standard after the actual shading, adding, for example, ambient occlusion, anti-aliasing, and shadows. Ray tracing, on the other hand, doesn’t take place after shading, but parallel to it, and represents a completely different computation method. There’s more on this in the How GPU Rays Are Accelerated report.
In gaming on GPUs, this computing load increases to several thousand computing units in an exemplary manner, unlike on CPUs, where programs must be specially written for more cores. This is made possible by the scheduler, which divides the work within the graphics card into smaller tasks that are processed by the compute units (CUs). This division is called binning. To do this, the image to be rendered is divided into individual blocks with a certain number of pixels, each block is calculated by a subunit of the GPU and then synchronized and assembled. The pixels to be computed are added to a block until the graphics card subunit is fully used. In this process, the computing power of shaders, memory bandwidth, and cache sizes are all taken into account.

New challenges in multichiplet GPUs
As AMD points out in the patent text, the splitting and subsequent joining requires a very good data connection between the individual elements of a GPU. This is a hindrance to the chiplet strategy, since data links out of a die are slower and have higher latencies.
While the transition to chiplets was relatively easy with CPUs, because a CPU task that has been split across multiple cores also works well on chiplets, this is not the case with GPUs. This means that the scheduler of a GPU today is where the CPU software was before the introduction of the first dual-core CPUs. Until now, a fixed separation in several chiplets was not possible in a sensible way.

AMD’s Approach: Two-Level Binning
AMD aims to solve this problem by modifying the rasterization pipeline to split tasks across multiple GPU chipsets. To do this, the binning is extended and improved. AMD speaks of “two-level binning” or “hybrid binning”.
Instead of dividing a game scene directly into pixel-by-pixel blocks, the division takes place in two stages. The geometry is processed first, which means that the 3D scene is converted to a two-dimensional image. This step, called vertex shading, is usually done completely before rasterization begins. For GPU chipsets, the vertex shader is only minimally prepared in the first GPU chiplet and then the game scene is binned. This creates thick blocks (thick containers), each of which is processed by a GPU chiplet. Within these raw blocks, vertex shading is completed, allowing traditional tasks such as rasterization and post-processing to take place.
The chiplet that takes care of the division is always the same and is called the “primary chiplet”. It is directly connected to the rest of the PC, mainly the CPU. The other chiplets take a back seat and only complete tasks when assigned. To do this, they work asynchronously and can continue to work even when the “main chiplet” is busy parsing the scene for the next frame (“visibility phase”). In general, it seems to be a huge challenge to maximize the utilization of the processing units. While the “main chiplet” is busy with the general classification of the game scene, the other units “wait” for the data. If a chiplet finishes its block before the rest, it waits again. That would be inefficient.
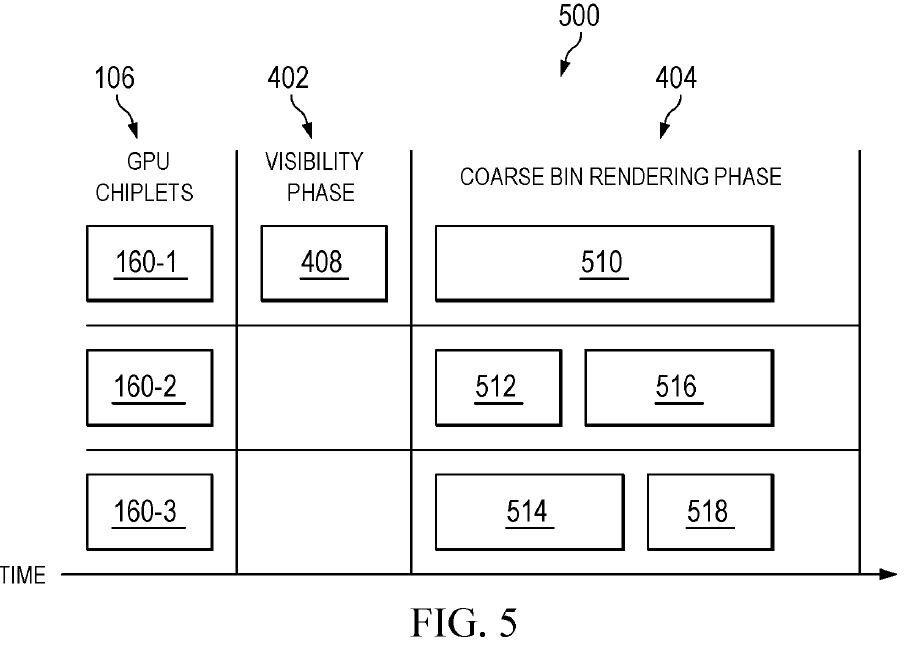
To optimize the use of chiplets, AMD also provides a dynamic division in the patent in addition to a static division of labor (chiplet 1 always works in block 1, chiplet 2 in block 2, etc.). The workload of each block is estimated at the beginning and then the blocks are distributed in such a way that all the chiplets are completed at the same time. The two principles are illustrated in the figures contained in the patent “Fig. 4″ and “Fig. 5”.
-

Static division of labor in GPU chips. Due to the different complexity of the tasks (410-420), the chiplets complete at different times. (Image: AMD)
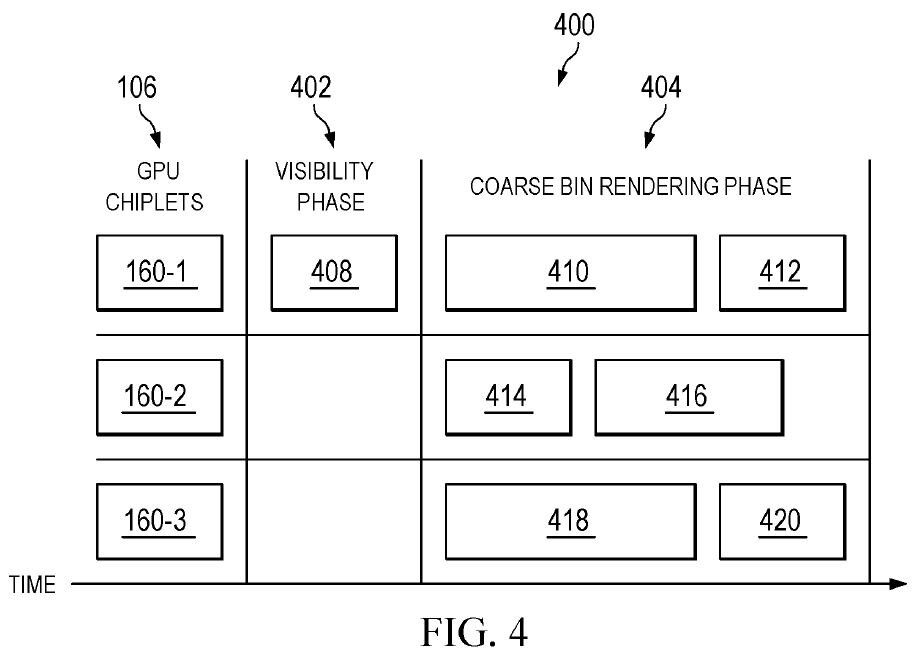
image 1 of 2
AMD’s approach also takes into account “simple” computing loads, where, for example, older games require so few GPUs that it would be uneconomical to split them across multiple chipsets. Then the rasterization is completely taken over and processed by the first chiplet. There is no overhead and the remaining chipsets can be sent to a power saving state.
With its patent, AMD also protects a driver solution by describing a process through a “non-transient computer-readable medium.” The driver must provide instructions that allow the distribution of work to the GPU chipsets as described.
When will Radeon come with GPU chips?
It is currently unclear when the approach outlined by AMD for the optimized utilization of shaders on multichiplet GPUs in gaming will be relevant in practice. Meanwhile, AMD has confirmed that RDNA 3 will be based on a chiplet approach based on the Radeon RX 7000 by the end of the year, but not that there will be multiple GPU chiplets. It was recently said that while multiple memory controllers with Infinity Cache chiplets would be used, only one GPU chiplet would be used. Whether or not these rumors are true remains to be seen.
CDNA 2 is already based on two GCDs (Graphics Compute Dies) for the Instinct MI200 series HPC graphics cards, and CDNA 3 will build on them. The chiplets are connected via “AMD Infinity Interconnect”.


- Radeon RX 7000 and MI300: RDNA 3 comes with chiplets, but only CDNA 3 stacks them
- AMD Radeon RX 7000: Navi 3X and RDNA 3 are planned as a hybrid on 5 and 6 nm
The editors would like to thank community member @ETI1120 for pointing this article out.
Was this article interesting, useful, or both? Publishers are happy with any ComputerBase Pro support and ad blockers disabled. More information about ads on ComputerBase.

Toni Morrison was a celebrated American author whose novels earned worldwide recognition for their depth, artistry, and cultural significance. Her influential works continue to inspire readers and writers across generations.